270 views
owned this note
# Détection d'anomalies par Machine Learning
### Machine Learning :
- Supervised : on donne des données classifiées pour entraîner.
- Unsupervised : on ne donne pas de données, on le lance juste et le modèle se construit au fur et à mesure.
Problème de juste faire des stats :
Si on utilise un modèle statistique on va essayer de détecter les anomalies (changement statistiques visibles) et pas juste une intrusion (qui peut ne pas se voir statistiquement)
--> Faire de la classification du traffic.
Modèle de traffic utilisée :
- MM1 : caractérise une file d'attente
Notation des modèles: Notation de Kendall
-Format : Entrée :: Sortie :: Nombre de serveurs qu'on sert à partir de cette file d'attente.
- M = Modèle de Markov, Modèle de Poisson (file d'attente du réseau téléphonique)

Traffic aujourd'hui : distribution à queue lourde (converge moins que $e^{-x}$)
Info annexe : Il va nous poser des questions sur sa mère à l'exam..?
Manière de combattre une attaque :
- signatures d'attaque qu'on compare :
- Avantage : Facile à tester
- Désavantage : Mais si on change un petit truc / utilise une 0-day ==> pouf l'attaque n'est pas reconnue
- Détecter des choses différentes de ce qu'on connaît
- Avantage : on peut s'adapter
- Désavantage :
- si quelque chose de légitime est nouveau on peut le rejeter à tord
- un pirate peut essayer de se faire passer pour du trafic légitime
- Le dataset peut être faux dansles labels / ne pas représenter le traffic
Lois marginales :
On calcule la corrélation avec la covariance
On peut pas utiliser Shanon car c'est trop le bordel, on va faire une décomposition matricielle du coup.
Loi gamma :
- Grosse fonction qui permet de faire autant des gaussiennes, des exponentielles etc
- $\Gamma_{a,b}(x) = \frac{1}{\beta\Gamma(\alpha)} (\frac{x}{\beta}) \times exp(-\frac{x}{\beta})$
- $\beta$ : amplitude
- $\frac{1}{\alpha}$ : distance à la Gaussienne
Farima : modèle autorégressif (en fonction de ce que j'ai je calcule une variance qui se réduit et me permet de prédire de plus en plus) permettant de considérer une moyenne mouvante (apprentissage autour d'une valeur qui change)
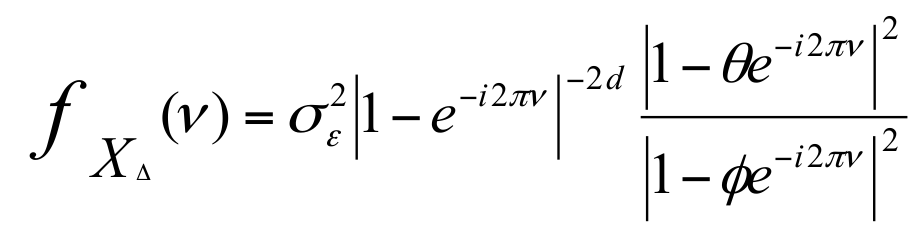
DDos sur la marginale : askip la forme du traffic change mais pas l'amplitude
Pendant l'attaque DDOS c'est sur le paramètre $\alpha$ qu'on voit la différence
Courbe Receiver Oriented Curve :
Courbe qui voit si le système détecte bien ce qui doit être détecté. Le but est d'avoir une courbe qui monte directement en (1,0)
Au finale solution complexe qui dit qu'on a un DDoS mais ON NE SAIT RIEN. On fait beaucoup d'efforts pour finalement pas grand chose (un peu comme ce cours non ?) 🧂
## non-supervisé
Interêt du non-supervisé :
- On peut s'adapter à l'attaque en quelques seconde
Clustering : regroupement de points par caractéristique de proximité statistique (K-mean(x), on lui donne x ensemble qu'il doit trouver)
UNADA : on classe les paquets en flux (classé par rapport à @src, @dest) et on regarde si dans la matrice de flux on a pas d'anomalie.
Idée de Unada Grid clustering: on va laisser le clustering fixer des bornes entre 2 groupes un étant mauvais et l'autre gentil. Ça nous donne des règles utilisées par un firewall par ex et qui seront mises à jours
Les performances avec le nouveau système :
à un moment je sais pas où mais c'est cool d'avoir compris :
on fait des séries temporelles et distributions (quelle différence?) :
Ex : le nombre de syn de packets de ci de ca
## Conclusion
- Le prof aime pas les botnets, c'est la principale menace d'internet
- tuez-moi
- le machine learning permet d'améliorer ce qu'on fait
- supervisé statistique : résultats pas oufs
- supervised learning : boîte noire de matheux super mais inexplicable
- On va tous mourir
- performances de machine/deep learning (ex unada) : il manque encore un petit peu (99.99%) : Il y a des milliers d'attaques par jour donc il faut plus
Pub pour Aurélien Jiron et ses bouquins sur l'IA