# Architectures des processeurs, langages d’assemblage et assembleur en ligne
- [Le cours](https://benoit.m0rgan.net/teaching/archi.html)
- [une fiche récap de l'x64](https://icscsi.org/library/Documents/Cheat_Sheets/Programming%20-%20x64%20Instructions.pdf)
## Info générales
### Vocabulaire
Assembleur $\neq$ Langage machine
L’assembleur est un langage de programmation, mais il est extrêmement proche du jeu d’instruction et de l’architecture d’un processeur (abstraction du langage machine)
En fonction de la famille de processeur / architecture on a plus au moins d’abstraction entre une instruction assembleur et le code réellement exécuté
Binaire ça veut rien dire → Une fois qu’il est chargé en mémoire *là* on peut parler de binaire, mais sur disque il est stocké dans un conteneur qu’on appelle exécutable (ELF, Windows)
Instructions gérée par un Microprocesseur
- processeur (ALU : calculs/opérations)
- mémoire (écrire/lire à tel adresse)
- Entrée / Sortie
- Flot d'exécution (sauts, fonction, interruption)
- Configuration du système/d'un processus avant le run
### Instructions de branchement
Les branchement utilisent le résultat d'une comparaison précédante qui est stockée dans des flags notamment :
- Z (Zéro) = si (résultat == 0) alors 1 sinon 0
- C (Carry) = retenue sur l’arithmétique binaire
- O (Overflow) = concerne l’encodage des nombres signés
- L’espace de nombre est coupé en deux par rapport aux entiers (la moitié pour les positifs, l’autre pour les négatifs)
- Overflow = 1 quand on peut pas représenter la valeur du nombre signé sur le nombre de bits qu’on a (on passe d'un nombre négatif à positif ou inversement)
Le compteur d’instruction (`pc`/`rip`) est normalement incrémenté de la taille de celle de l’exécution courante pour passer à la suivante.
Avec le branchement on voit qu’il y a la non-linéarité d’exécution, il faut pouvoir changer la méthode de modification du compteur ordinal
2 types de branchement : conditionnels (on va peut-être brancher) et inconditionnels (on va toujours brancher)
Prédicat en langage C : faux quand = 0 (il est dans le if (…) ), vrai dans tous les autres cas
En assembleur le bloc `then` est après la comparaison, suivi par le `else`.
Dans le cas où le prédicat est vrai ⇒ on ne branche pas (pour executer le corps du if) puis on branchera à après le then.
```c
if (v == 0) { ... }
```
Dans le code au dessus, si v est vrai alors on ne branche pas (on saute le bloc if ?), en langage assembleur la condition va être inversée (ce ne sera plus “si v est faux”, ce sera “si v” avec inversion des branches)
La seule différence entre un `if` et un `while`/`for` c’est qu’à la fin de la branche conditionnelle, on va rajouter un saut / retour inconditionnel vers l’évaluation de la condition (au début du calcul du prédicat servant au branchement)
Pour un branchement conditionnel, le processeur va raisonner avec le résultat d’une opération arithmétique qui précède.
Exemple : Si on veut vérifier que deux valeurs sont égales, on peut les soustraire, si le résultat est zéro alors on aura un flag / fanion (= drapeaux arithmétiques) qui indique que le résultat est 0, et c’est ce flag que le processeur va regarder
On a plein d’instructions de branchement `jcc`, `jne` (jump if not equal), `je` (jump if equal), etc.
### Fonctions et procédures
Objectif de fonctions et procédures → Factoriser, réduire la taille du code
En assembleur un appel de fonction sera un branchement inconditionnel, avec en plus la sauvegarde de l'addresse de l'instruction qui suit (dans un registre comme `LR` en ARM)
➡️ On crée donc un instructions de branchement spéciale qui va faire ça `call`
Par contre on accepte un seul niveau de récursion, si on imbrique une fonction dans une fonction alors comme notre registre de retour est écrasé on ne sait pas où retourner.
Pour pouvoir faire des fonctions qui en appellent d'autres, il faut le sauvegarder et le restaurer (on va utiliser la pile en mémoire parce qu’on a un espace de registres limité) pour savoir à chaque fois où revenir.
*NB : on peut optimiser la fonction "feuille" en ne sauvegardant pas l'addresse de retour dans la mémoire vu qu'elle ne sera pas écrasée*.
||
| --- |
| f3 |
| f2 |
| f1 |
| f0 |
| main |
C’est vraiment comme ça qu’on fait dans les processeurs
Dans le cas d’un appel récursif on va empiler les adresses de retour à la même fonction jusqu’à ce qu’on fait finit tous les traitements récursifs et qu’on retourne à main
- Jeux d’instructions à taille fixe (ARM → 4 octets alignés, MIPS)
- Jeux d’instruction à taille variable (x86)
Structure d’une instruction = `OpCode [? Operandes]` (e.g. `add r0, r1`).
L'opCode permet de savoir quel hardware sera utilisé, sur quelle taille sera l'opération si on utilise une taille variable (ex x86).
### Syntaxes et Modes d’adressage
syntaxe :
- % → registre
- $ → valeur en tant que telle
- (X) → accès en mémoire à X (X peut être un registre ou une valeur)
- d(X, ind, taille) → accès en mémoire à X + ind $\times$ taille + d (idem qu'avant pour ind taill et d)
#### Addressage de branchement
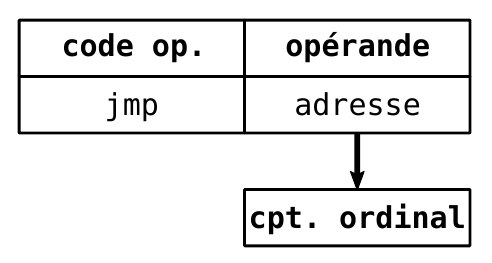
- Absolu
- `jmp <adresse>`
- 
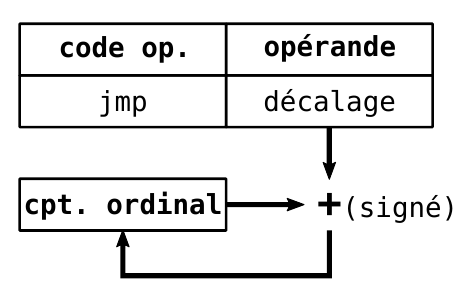
- Relatif (on a besoin du contexte pour savoir où on va)
- `jmp <offset>` (offset nombre signé)
- 
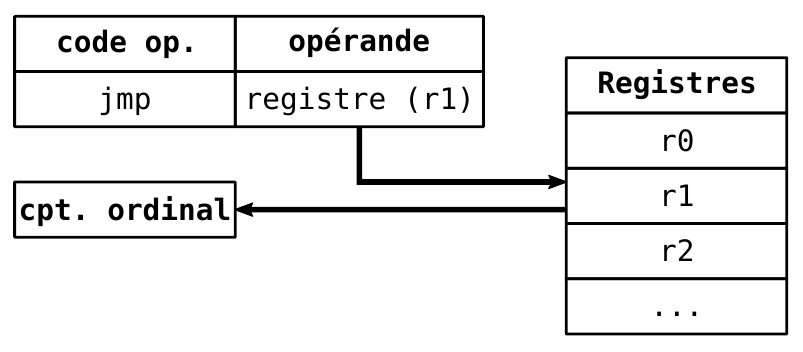
- Indirect (e.g. on va jump à l’adresse contenue dans un registre)
- `jmp *%rax` `jmp *0x1234` `jmp *(%rax)`
- Sur processeur Intel on a aussi une instruction pour faire un jump à une adresse *en mémoire* (donc on va lire une adresse mémoire dans un registre, regarder à cette adresse mémoire l’adresse à laquelle on doit jump), c’est super lent bien sûr
- 
#### Addressage de données
- **Immédiat**
- `$12`
- 
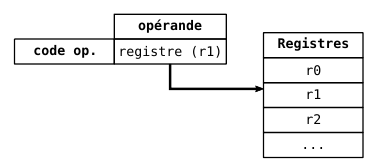
- **registre**
- `%rax`
- 
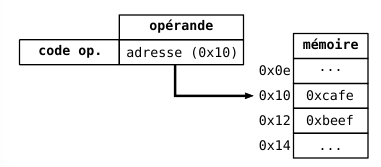
- **absolu**
- `(0xff10)`
- 
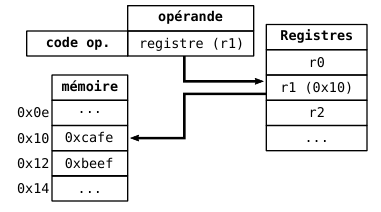
- **Indirect registre**
- `(%rax)`
- 
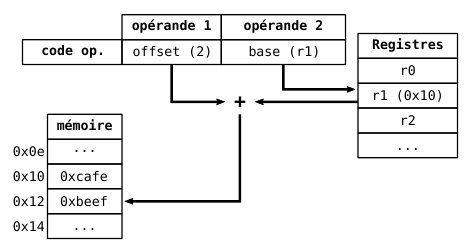
- **Indirect base (registre) avec décalage**
- `m(%rax)` -> MEM[rax + m]
- 
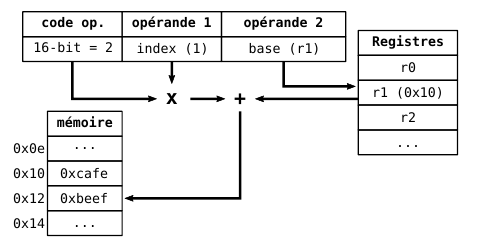
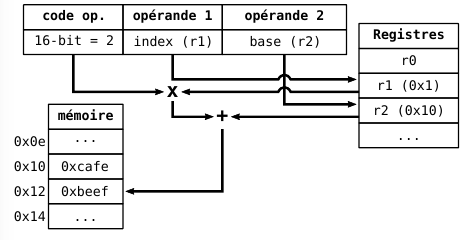
- **Indirect base (registre) avec index absolu**
- L'index absolu est multiplié par la taille d'un élément pour avoir le décalage
- `(%rax, %rbx, n)` -> MEM[rax + rbx × n]
- `m(%rax, %rbx, n)` -> MEM[rax + rbx × n + m]
- 
- **Indirect base (registre) avec index registre**
- L'index contenu dans un registre est multiplié par la taille d'un élément pour avoir le décalage
- `(%rax, %rbx, %rcx)` -> MEM[rax + rbx × rcx]
- `m(%rax, %rbx, %rcx)` -> MEM[rax + rbx × rcx + m]
- 
🦸 On peut également ajouter un **Décalage** (rentré en dur ou récupéré dans un registre, ou **les 2**) ou un **Index** (nombre de fois à répéter le décalage).
Processeur 64 bits = taille de registre (et du coup affecte la taille des opérations arithmétiques qu’on peut faire) | Adresse est en 48 bits
## Intel x86 :
Registres :
- Pointeur d’instruction : ip
- Généraux : a,b,c,d,r[8-15]
- Tete de pile : sp
- Base de pile : bp
- Index, copie en mémoire : si, di (source et destination)
- Drapeaux d’état [er]flags : c, z, o, …
registres en fonction de la taille :
- 8 bit : [abcd][lh] : l pour le 1er octet, h pour le 2nd
- 16 bit [abcd]x
- 32 bit e[abcd]x
- 64 bit r[abcd]x
- 
ATTENTION : mov MEM[a], MEM[b] → Impossible, c’est un truc du genre mov MEM[a], b
<!-- à maybe pas garder La première opérande est celle la plus à gauche (🚧 Ce n’est plus vrai pour l’assembleur GNU) -->
### Rappels de compilation/debug:
**Compilation ASM** :
- `as` permet de transformer le texte ASM en fichier `.o`. (ne résoud pas les symboles)
- `nm` permet de voir les symboles exportés (que l'éditeur de lien pourra retrouver) dans un .o ou binaire
- T --> symbole exporté
- U --> symbole non trouvé
- t --> symbole non-exporté
- `ld` --> édition de lien et ajoute __bss_start, _start, _end qui servent etc
*On peut utiliser le flag `-g` sur `gcc`, `as`, `ld` pour pouvoir utiliser facilement gdb*
### Utilisez GDB
commandes principales (à regarder dans la fiche):
- `run [? ...Arguments]` --> Lancer
- `l [fichier][:l]` : affiche le code [de tel fichier] à telle ligne
- `b/hb [fichier] ligne/symbole/*addresse` --> set un breakpoint, mettre un : entre nom de fichier et ligne
- `c` --> Continuer après breakpoint
- `s[?i]` --> ligne suivante C ([assembleur])
- `n[?i]` --> ligne suivante C ([assembleur]) mais SANS rentrer dans les fonctions. On reste au même niveau
- `info frame/registers` --> afficher la stack frames/registres
- `bt` --> affiche la stack frame, permet avec `frame X` d'aller à la frame X
#### [Fiche de triche GDB](https://benoit.m0rgan.net/assets/supports/gdb-cheat-sheet.pdf)
Infos :
- Hardware breakpoint (le CPU appelle quand on est à telle addresse)
- Software breakpoint (on patch le code pour mettre un stop à cet endroit là)
### Syntaxes
Manuelle dev Section 2 → TOP
Syntaxe d'un petit programe ASM :
- `_start` --> met en place les arguments et appelle `main` (en C)
- `OPCODE [?OP2, OP1]` (Ex : `SUB %rax, %rbx` donne $b-a$)
- `//` pour commenter
- `.global SYMBOL` exporter un symbole : permettre aux autres .o de le lire
- Pour faire un appel system : op `SYSCALL` (il lira ses paramètres dans les registres)
Pour avoir les numéros d'appel system : unisd_64.h
⚠️ En GNU : `CMP %a %b; JG` ⇒ correspond à b>a vu que l'opérande 2 est le premier.
### ABI Application Binary Interface
Permet aux fonctions de savoir où est tel argument (registre puis mémoire (pile)). Donne également quels arguments sont dans quel ordre mais aussi, qui (appellant ou appellé) empile/dépile les arguments.
Example :

En x86, en une seule instruction `call` on a l’empilage de l’adresse de retour *et* le saut inconditionnel à l’adresse de la fonction. Par contre il faut placer les arguments avant et dépiler si on a empilé après.
Idem pour l’instruction `ret` qui en une instruction fait le saut inconditionnel à l’adresse de retour *et* dépile l’adresse de retour
`xSP` pointe *toujours* vers la case qui est la tête de pile, pas la prochaine case
`xBP` pointe *toujours* sur le base de la frame ce qui permet de déterminer facilement la position de variables.
On représente toujours une pile qui monte, mais en réalité dans le processeur ça descend par défaut.
En début de fonction
- Soit `enter <@>`
- `push xBP`, `xBP = xSP`, `xSP = xSP - taille`
En fin de fonction
- Soit `leave` puis `ret`
- `xSP = xBP`, `pop xBP` ou `sp = xSP + taille`
[Exemple & Doc](https://notes.ar-lacroix.fr/s/fGdn61XRW)
`execve()`: j’écrase l’intégralité de mon processus avec le code d’un nouveau programme
## ASM Inline
Deux façons d’interfacer l’assembleur inline en C
- Template Normale (copier / coller de l’assembleur qu’on écrit en C, corruption potentielle de registre, éclater son programme). Permet de mixer ASM et C, notamment quand on a besoin de quelque chose qui n'est pas en C.
```c
asm volatile(
"xxxxxx \n" // on peut ajouter un "\t" pour que ça soit alligné
"xxxxxx \n"
)
```
*`Volatile` pour ne pas être optimisé*
- Template Étendu (mode vener, bien s’interfacer avec les types en C)
- On peut spécifier les registres qu’on corrompt (et du coup ça les protège)
- Aussi spécifier les entrées et les sorties (pour pouvoir faire l’interface avec du C sans tout démolir)
- Pas de l’assembleur pur, il sera pre-processed
- language du template
- % --> contrainte
- %% % escapé
- Contraintes dans les entrées/sorties :
- `"a" (variable/valeur)` ==> a est en entrée ([er]ax prendra la valeur de variable/valeur) (marche pour a, b, c, d, r8-15, m ...)
- `"=a" (variable)` ==> a est en sortie (on écrira dans a)
- `"+a" (variable)` ==> a est en entrée/sortie
- `"m"` ==> mémoire
- `"i"` ==> entier immédiat
- `"g"` ==> n'importe où
- `"r"` ==> dans n'importe quel registre
- `"mabc"` ==> on laisse le choix du meilleur de la liste
<!-- regarder la doc -->
```c
asm volatile(
"template \n"
: "sorties (et entrées/sorties) \n"
: "entrées \n"
: "quels registres je vais tapper et que tu dois sauvegarder \n"
)
```